2022年被誉为是AIGC元年,在这一年,随着文心一格、ChatGPT等消费级AI应用的诞生,原本普通人难以接触到的人工智能技术终于走进了千家万户,其中ChatGPT更是创造了短短3个月用户量破亿的惊人表现,成为了史上最快达到亿级用户的应用。关于ChatGPT背后的技术,随着文心一言即将问世,厂内已经有很多大神进行了分享。今天,我们来聊一聊文生图(text2img)这项AI技术背后的机器学习算法支撑—扩散模型,及其改进版本—稳定扩散模型。读完这篇文章,也希望大家可以动动手,在实践中打造一款属于自己的AI应用~
生成式模型
扩散模型属于一个名叫「生成式模型」(Generative Models)的机器学习模型大家族,这个大家族里人员众多,细分成很多派别,有的擅长生成图像和声音,有的擅长生成代码片段。它们的分类也多种多样,比如按照学习方式分,可以分为有监督督学习模型的和无监督学习模型;按照模型结构分,可以分为基于概率的模型和基于神经网络的模型。常见的生成式模型包括生成对抗网络(GANs)、变分自编码器(VAEs)、扩散模型(DMs)等,广泛应用于图像生成、文本生成、语音合成等领域。
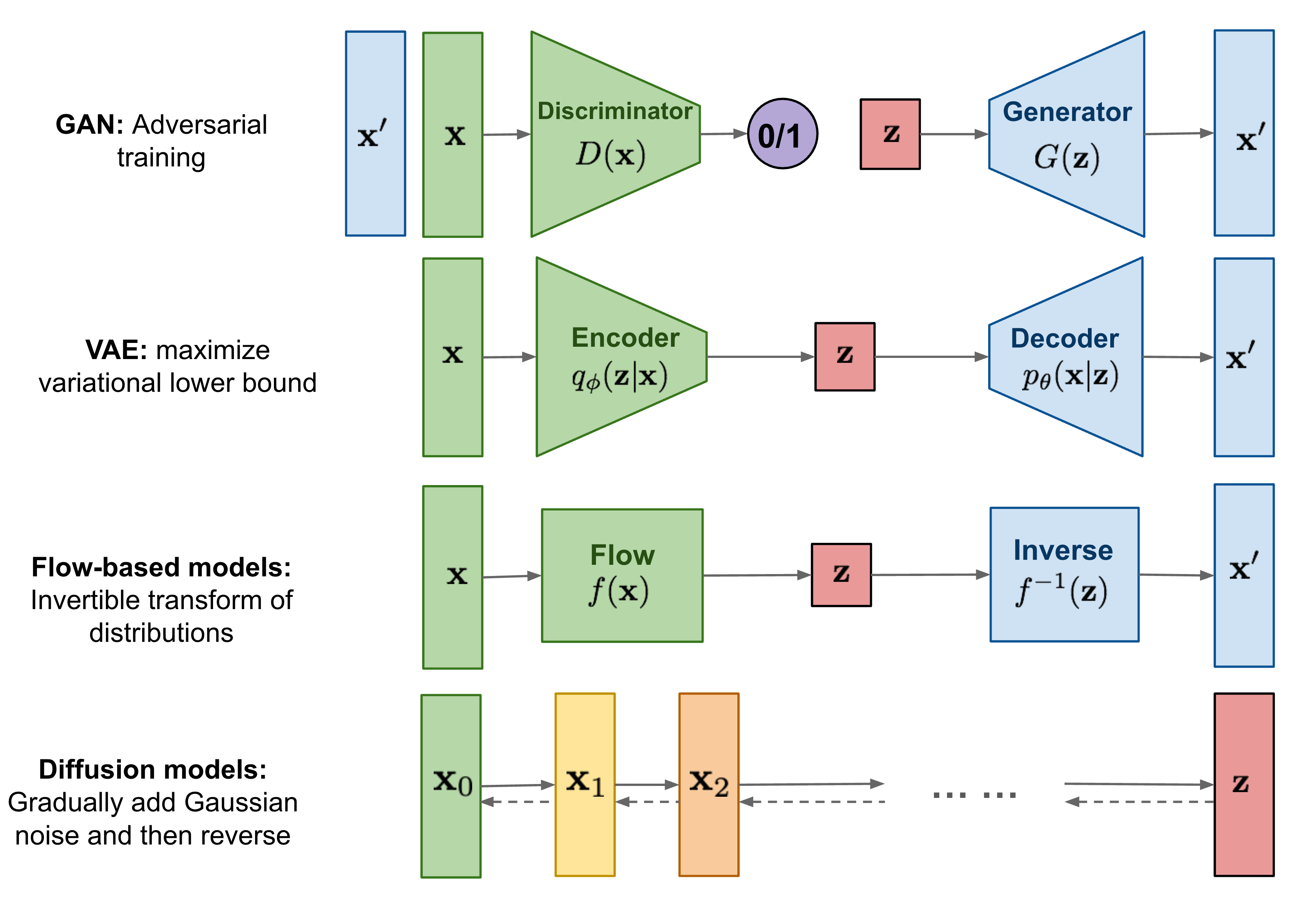
它们的原理及区别如上图所示,以下对这几种生成式模型进行一个简单的介绍:
- 生成对抗网络模型(GANs)是一种基于采样的生成式模型,由两个神经网络组成:一个是生成器(Generator),一个是判别器(Discriminator)。生成器的目标是从随机噪声中生成与真实数据相似的数据,判别器的目标是区分输入的数据是真实的还是生成的。两个网络相互博弈,不断提高自己的能力,最终达到一个平衡点,使得判别器无法区分真假数据。这种模型训练不稳定,多样性较少。
- 变量自动编码器模型(VAEs)是一种基于概率的生成式模型,它由一个编码器(Encoder)和一个解码器(Decoder)组成。编码器将输入数据映射为一个低维的潜在空间,这个空间通常是一个多元高斯分布,编码器的输出是这个分布的均值和方差。解码器将从潜在空间采样的随机向量重构为与输入数据相似的数据。变分自编码器通过最大化数据的边缘对数似然来训练,同时也最小化了输入数据和重构数据之间的差异。
- 扩散模型(DMs)是一种基于采样的生成式模型,它通过不断向数据添加噪声,使数据从原始分布变为简单分布,例如正态分布。然后,它通过学习一个逆扩散过程,从噪声中恢复出原始数据。
用一句话简单概括,生成式模型是一类能够根据已有数据的分布情况,生成新的数据的统计模型。
扩散模型
扩散模型是「生成式模型」算法家族的新成员。上一节我们已经简单介绍过几种生成式模型,这些模型通过学习给定的训练样本,可以学会如何生成数据,比如生成图片或者声音。它们的显著特点是,能生成一组样式不同的输出,这些输出与训练数据非常相似,但不是一模一样,更像是不同样本的组合。扩散模型是如何实现这一点的呢?让我们通过下方的图示,简单了解下通过扩散模型训练的过程:
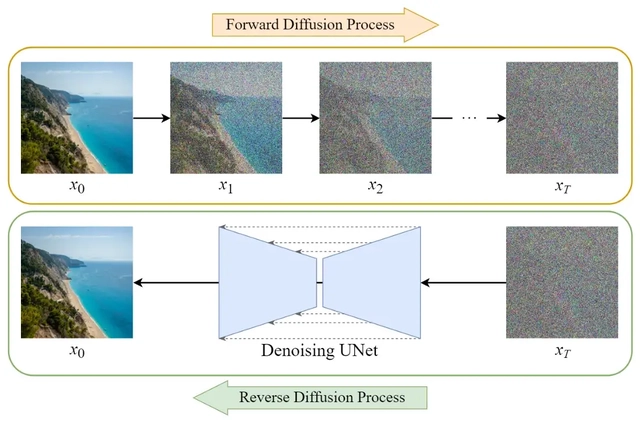
可以看到,通过不断向样本数据添加噪声,使数据从原始分布变为简单分布(如高斯分布)。然后进行逆扩散过程,通过多次迭代采样进行去噪,从简单分布中恢复出原始数据。
与GANs等模型相比,扩散模型的优点如下:
- 可以生成高质量的图片,清晰度比其他生成式模型高
- 可以很容易地加入类别条件或文本条件
- 因为是用固定的程序学习的,而且隐变量具有高维度(与原始数据相同),这使得模型具有更好的可解释性
但同时,使用该模型时因为有一个迭代采样的过程,导致模型训练和预测效率低,训练和推演成本高昂。这使得用户在使用时,在多样性和定制化上仍具有很大局限性。
目前已经有很多成熟的开源项目,可以让用户基于扩散模型进行训练,如美国抱抱脸公司开源的diffusers项目:
https://github.com/huggingface/diffusers
该项目不但提供了预训练、亿级别样本的模型库,而且提供了可视化界面及用于模型训练的工具包。
潜在扩散模型和稳定扩散模型
基于扩散模型存在的一些问题,Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser 和 Björn Ommer五位学者发表了名为「High-Resolution Image Synthesis with Latent Diffusion Models」的论文,提出了潜在扩散模型(Latent Diffusion Models)。
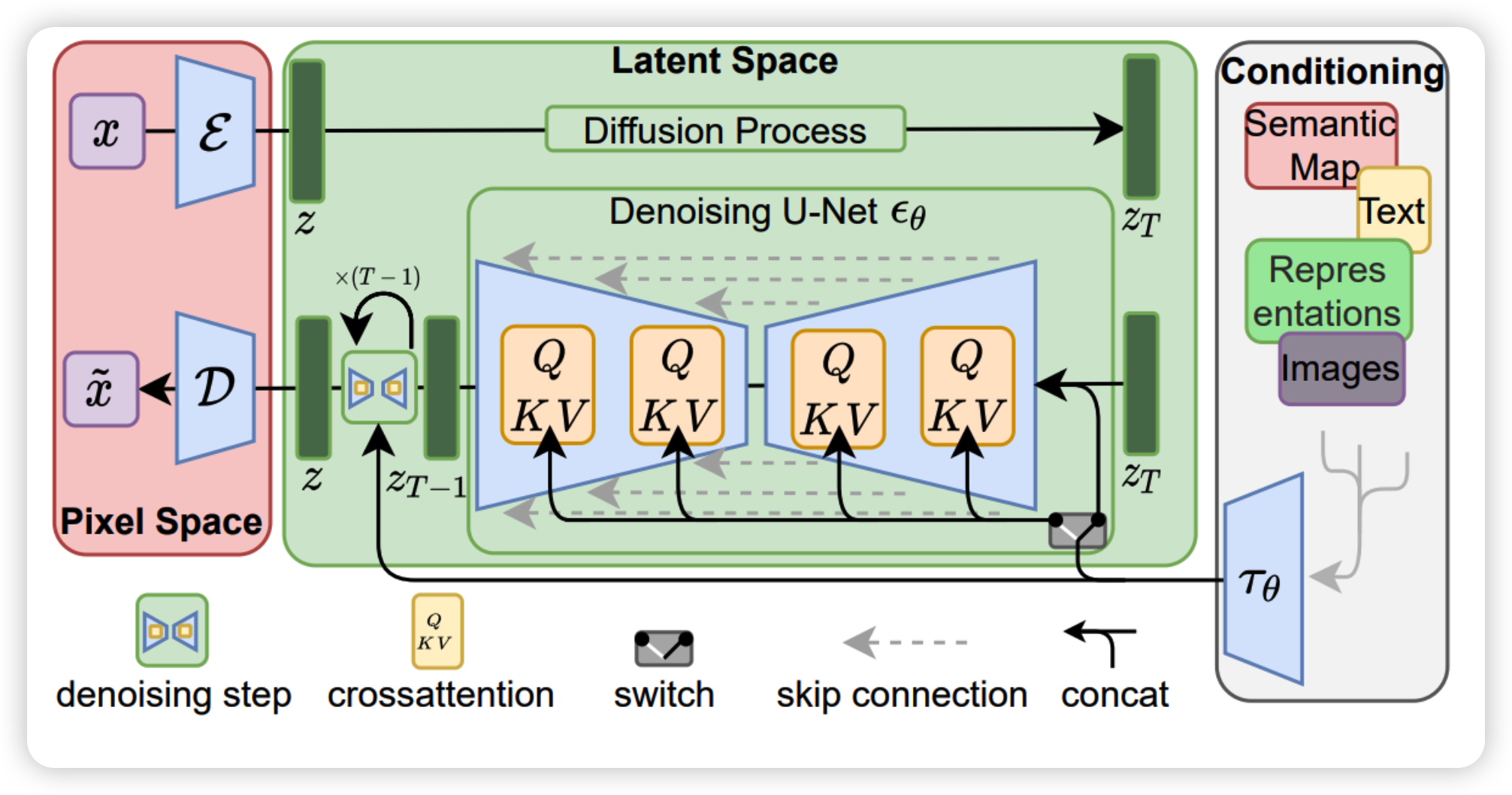
潜在扩散模型(LDMs)在原始扩散模型的基础上进行了优化,引入低维潜在变量,可以在低维潜在空间中对图像进行编码和解码,从而提高生成质量和效率。潜在扩散模型的优点有:
- 在复杂性降低和细节保留之间达到一个接近最优的点,极大地提高了视觉保真度
- 可以将扩散模型转化为强大而灵活的生成器,用于文本或边界框等一般条件反射输入,并以卷积方式实现高分辨率合成
- 与基于像素的扩散模型相比,显著减少了计算需求
稳定扩散模型(SDMs)是基于LDMs改进的扩散模型,它通过使用一个固定的噪声方差序列,使得每个扩散步骤都能保持数据的语义结构。提出该模型的CompVis研究组基于LDMs进行了扩大训练,在Laion-5B数据子集上使用了超大规模的约25 亿「文本 - 图像对」进行训练,取得了非常显著的效果。
基于稳定扩散模型的文生图原理如下图所示:
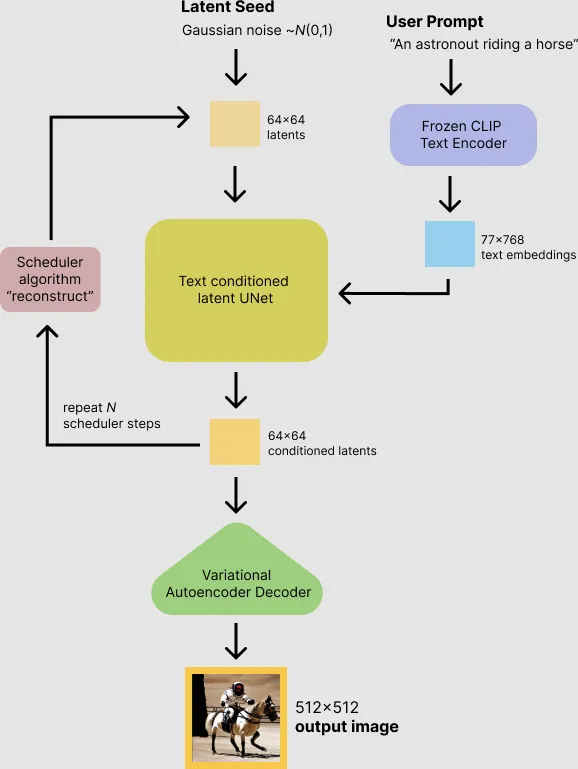
上述流程不难理解:我们输入文本提示,即「宇航员骑马」,Frozen CLIP Text Encoder组件对文本进行编码后,将文本embeddings传递给扩散模型,该模型将随机噪声添加到图像中,利用这些信息训练文本/图像编码器。然后,编码器经过N次迭代,在图像块上添加更多的噪声。最后,Variational Autoencoders组件猜测文本和图像的哪个组合最能代表初始的文本提示。然后输出最佳匹配的图像。
这其中有一个很重要的组件叫做Frozen CLIP Text Encoder,它是一个基于「CLIP ViT-L/14」神经网络的文本编码器。由于它的存在,稳定扩散模型具备了基于User Prompt生成图像的能力。CLIP本质上是一个预训练的「文本-图像对」神经网络。下图是CLIP训练的第一步,将N张图片的自然语言文字描述作为一个输入,图片本身作为另一个输入,对应的「文本-图像对」(N个)作为正激励,不对应的「文本-图像对」(N^2-N个)作为负激励,进行训练。CLIP详细的训练过程大家有兴趣可以深入研究,在此不再赘述。
稳定扩散模型作为一种深度学习文生图模型,有如下优点:
- 可以生成更高质量和更多样化的图像
- 不会受到模式崩溃的影响,即不会生成重复或无意义的图像
- 可以与其他生成式模型(如GANs或VAEs)结合,提高生成效率和性能
- 可以在消费级 GPU 上的 10 GB VRAM 下运行,并在几秒钟内生成 512x512 像素的图像,无需预处理和后处理
该模型已经在github上开源:
https://github.com/CompVis/stable-diffusion
为了进一步降低使用这一模型的门槛,诞生了很多开源项目为SDMs提供更符合普通用户使用的Web UI界面,简单来说就是对底层技术进行了封装,用户不再需要输入命令行,而是通过可视化界面去进行操作。比如由用户推出的AUTOMATIC1111版Web UI:
https://github.com/AUTOMATIC1111/stable-diffusion-webui
但是使用这一项目仍然需要具备一定的计算机编程基础。对于真正零算法基础的用户来说,即使能够通过可视化界面进行操作,前期安装python环境和各种库还是会有一定门槛。所以基于stable-diffusion-webui又诞生了各种插件和扩展,使用户可以在谷歌浏览器、Photoshop甚至PS5游戏机上通过远程调用的方式使用文生图进行创作。尤其是支持在Photoshop上进行图像生成并进行二次创作,能够切实提升设计师的生产力。总的来说,这项AI技术目前已经非常接近AI普惠的概念了。
展望未来
可以预期的是,Stable Diffusion绝不会止步于文生图、图生图领域,今明年可能就会进入短视频领域。随着未来算力的进一步解放,三维动画、建筑设计领域也将很快看到这一模型的身影。
内容创作是一个万亿级的市场,在很多人还对AIGC这一概念不甚了解的时候,一些敏锐的人已经开始尝试通过AIGC进行商业变现了,在AI的协助下交付广告创意、插画设计等,甚至出各种关于AI辅助创作的付费课程。不论你是设计师还是热爱创作的普通用户,相信今天介绍的这项AI技术都会给我们的工作带来很大助力,激发我们的创意(当然最终也可能会替代设计类工作-_-)